-
2 Neural Network BasicsAI/Machine Learning 2023. 2. 6. 16:05
🧚🏻♂️ 참고 자료 링크
- Back propagation
- Gradient Descent * Learning Rate
누구나 이해할 수 있는 딥러닝 - cs231n 4강(Backpropagation and Neural Networks)
[머신러닝] 경사 하강 알고리즘(Gradient Descent Algorithm)이란
[머신러닝] 경사 하강 알고리즘(Gradient Descent Algorithm)이란
시작하며 이번 포스팅에선 비용 함수(Cost Function)의 비용값을 최소화 하는 파라미터 θ를 찾는 경사 하강 알고리즘(Gradient Descent Algorithm) 에 대해 공부해보겠습니다. 경사 하강 알고리즘(Gradient Desc
box-world.tistory.com

Neural Network에서 가장 중요한 수식이라 할 수 있겠다. Neural NetWorks
- Neraul networks는 Mappings 을 하는 수학 모델이다.

- Vector : 길이 고정
- Sequence : 길이가 고정되어 있지 않음 ex) 자연어
- Mapping 예제

- 위와 같이 Mappings을 잘하는 모델 외에도 확률분포를 잘 학습하는 네트워크도 있다.
- Sample generation
- ex ) 비슷한 사람 얼굴을 만들어 내기
- Sample generation
- Restoration
- 값 두개의 소실된 정보를 갖고 있기
- Transformation
- 흑백 영상으로 Color 영상 만들기 (많은 패턴을 학습하게 하여 이에 입각하는 결고라를 출력하게 하는 것)
Perceptron Neuron
- Activation Func, Why?..

Linear 한상태로 값을 축적 시키면 아무리 Layer가 많아 진다 하더라도 Linear 하게 나타난다 → 즉, 간단한 값 밖에 출력 못함 .. 
weight 구하는 식, 2차원 배열 형태의 incoming Weight에서 weight를 불러오고 사용하는 방법에 대해 말하고 있다. Percentron 예제


- 원점을 지나는 직선의 방정식이 나온다. (bias : 0)
- 노드 개수 == 직선 개수
- 학습 → 최적의 weight 구하기
Training of Single Layer Perceptron
- Mappings에 최적화된 weights 생성 방법
- 랜덤 값으로 초기화


Gradient descent(경사하강법)

- o : 실제 출력
- d : Label 값
- 2로 나누는 이유, 미분을 할때 나오는 제곱근 2의 값을 없에기 위한 트릭

https://box-world.tistory.com/7
[머신러닝] 경사 하강 알고리즘(Gradient Descent Algorithm)이란
시작하며 이번 포스팅에선 비용 함수(Cost Function)의 비용값을 최소화 하는 파라미터 θ를 찾는 경사 하강 알고리즘(Gradient Descent Algorithm) 에 대해 공부해보겠습니다. 경사 하강 알고리즘(Gradient Desc
box-world.tistory.com
Error Minimization Technique
- 역전파 과정을 통해 에러를 줄인다.

Error와 Desecent의 상관 관계 정의 - Error와 Desecent의 상관 관계 정의
Gradient Descent

에러 그래프의 저점, 즉 에러가 가장 작은 분을 찾기 위한 방법 
에러와 weight의 관계를 정리하기 위하여 chain rule을 사용하여 수식을 구한다. 
나온 결과 값을 갖고 식을 업데이트 한다. Learning Rate

학습 보폭(속도)으로 이해하면 편하다. - Learning Rate 가 지나치게 작을때
- 연산횟수 증가
- Learning Rate 가 지나치게 클 때
- 원하는 값을 지나친다.
- [보통 0.001, 0.01 사용]
- 문제가 단순 키우기
- 문제 복잡 작게
- [보통 0.001, 0.01 사용]
- 적당한 Learning Rate 사용
- 값이 수렴하지 않을 수 도 있다.
- 원하는 값을 지나친다.
Training Algorithm(알고리즘 학습)

앞으로 많이 등장할 파라미터다. 
맨위에서 강조햇던 식, 에러를 구하는 식, 위에서 chain Rule 을 이용하여 구했던 식들이다. Multi-layer Perceptron

XOR 연산이 안되는 SLP의 한계를 보안한 것 활성함수란?

weighted Sum 한 것을 한번 더 처리 해주는 것 Example of Activation Functions

SoftMax
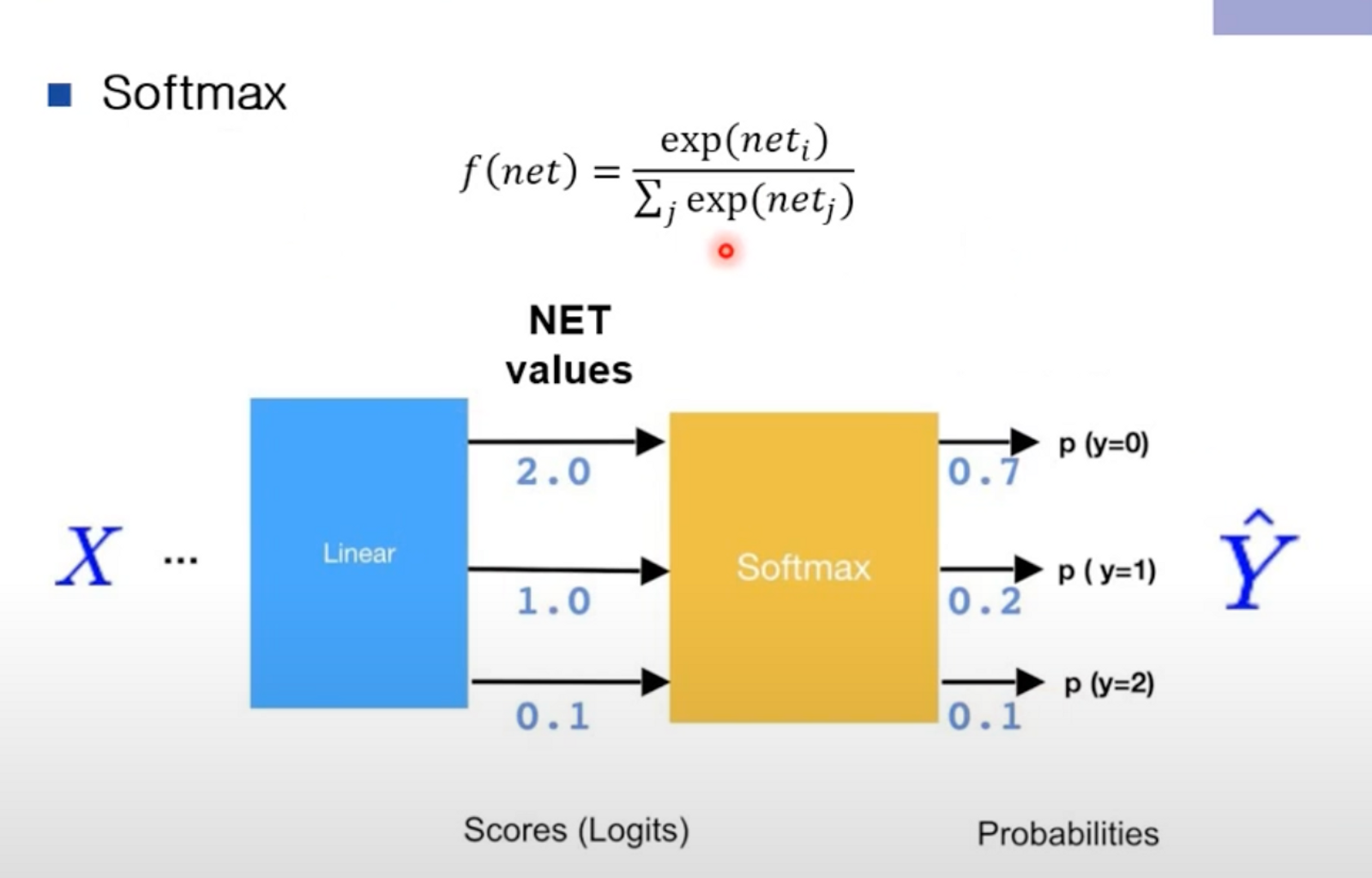
- Net Values는 확률을 나타내는 값이 아니다
- 따라서 SoftMax 함수를 이용하여 나타낸다.
각각 상황에 맞게 활성 함수를 사용해야 한다.

- Recurrent Network에서는 Relu 사용주의해야한다.
Loss Funciton


밑에 블로그에서 캡쳐한 내용이다. Cross-entropy 의 이해: 정보이론과의 관계
Cross-entropy 의 이해: 정보이론과의 관계 1. 손실함수로서의 Cross-entropy 딥러닝에서 분류 모델에 대한 손실 함수로 cross-entropy 혹은 binary entropy 나 log loss 라는 것을 사용하게 된다. 손실함수로서의 cr
3months.tistory.com
++ 추가적인 내용
- 스칼라를 벡터로 미분 → Gradient
- 벡터를 벡터로 미분 → Jacobian law
'AI > Machine Learning' 카테고리의 다른 글
Clustering (0) 2025.02.17 Density Estimation (0) 2025.02.17 Machine Learning math background part 2 (0) 2025.02.13 Machine Learning math background (0) 2025.02.13 Introduction to Machine Learning (0) 2023.02.06