-
MonoTDP: Twin Depth Perception for Monocular 3D ObjectDetection in Adverse ScenesAI/논문리뷰 2025. 4. 13. 21:56
오늘 리뷰 해볼 논문은 MonoTDP 라는 논문이다.
Monocular 3D detection 논문을 읽으며, adverse(fog, rainy.. )를 위주로 찾아보고 있다.
관련된 라이더 기반 연구들은 꽤 있지만, Monocular 3D detection 연구는 없다.
해당 논문은 ICASSP 2024 에 기제된 논문이다. 제출 포멧에 맞추기 위해서 논문을 읽어보면 아주 간소화 되어 있다.
https://ieeexplore.ieee.org/document/10446148
AEAM3D:Adverse Environment-Adaptive Monocular 3D Object Detection via Feature Extraction Regularization
3D object detection plays a crucial role in intelligent vision systems. Detection in the open world inevitably encounters various adverse scenes while most of existing methods fail in these scenes. To address this issue, this paper proposes a monocular 3D
ieeexplore.ieee.org
좀 더 찾아보니, 여기에 좀 더 풀어서 설명된 MonoTDP 라는 논문이 있었다.
저자를 보니 이름도 겹치는 사람들이 있다.

MonoTDP: Twin Depth Perception for Monocular 3D Object Detection in Adverse Scenes
3D object detection plays a crucial role in numerous intelligent vision systems. Detection in the open world inevitably encounters various adverse scenes, such as dense fog, heavy rain, and low light conditions. Although existing efforts primarily focus on
arxiv.org
과연 이 논문은 어떻게 Monocular 상황에서 adverse scence을 어떻게 다뤘을지 보도록 하자.
Motivation
연구에서 제안하는 동기는 다음과 같다.
기존의 단안 3D 객체 탐지 기법은 (1) M3D-RPN, MonoDLE처럼 단일 이미지를 활용하는 방식과 (2) RoI-10D, Pseudo-LiDAR처럼 보조 정보를 활용하는 방식으로 나눌 수 있다. 하지만 이 방법은 다음과 같은 한계를 갖고 있다.
- 실제 환경에서의 악천후로 인한 이미지 품질 저하,
- 단일 시점의 한계로 인한 깊이 추정의 불확실성,
- 악천후 상황을 반영한 데이터셋 부족.
이러한 문제를 해결하기 위해, 우리는 MonoTDP 라는 새로운 단안 3D 객체 탐지 방법을 제안한다. 이 방법은 복잡한 환경에 적응할 수 있는 학습 strategy를 포함하고 있고, 7가지 악조건이 포함된 다양한 데이터셋도 함께 제시한다.

Figure 1은 제안한 모델이 기존 SOTA 기법과 이미지 보정 + 탐지 모델을 능가함을 보여준다.Overall Architecture

전체구조는 크게 Adaptive Learning Strategy 와 Twin Depth Perception 으로 나뉜다.
Adaptive Learning Strategy에서는 악조건(Adverse Scence) 환경에서 강건한 피쳐들을 효과적으로 추출할 수 있는 것을 목표로하며, 이를 위해 WCE(Weak Constaint Encoder)와 SCD(Strong Constraint Decoder)를 도입한다.
Twin Depth Perception은 객체의 깊이를 더 정확히 예측하기 위해 전체 깊이를 scene depth 와 object D
Method
Adaptive Learning Strategy
- Weak Constraint Encoder
- Strong constraint decoder
Twin Depth Perception
- objects depth info + scene depth info
- Reflect Uncerntainty
Dataset
자율주행 환경에서는 비, 안개, 저조도 같은 다양한 날씨 조건에서 인식률이 크게 달라진다. 하지만 기존의 KITTI 데이터셋은 대부분 맑은 날에 촬영된 영상으로 구성되어 있어, 실제 운전 환경의 다양한 조건을 반영하기 힘들다.
따라서 해당 논문에서는 기존 KITTI 이미지에 날씨 효과를 합성하여 새로운 데이터셋을 만들었다.

1. 안개
안개는 Atmospheric Light Attenuation Theroy 에 기반 하여 다음과 같은 수식으로 모델린된다.

Atmospheric Light Attenuation Theory 
light propagation formula - I : 최종적으로 안개가 낀 이미지
- B : 원본 배경 이미지
- A: atmopheric light
- T : 빛의 전파 정도를 나타내는 투과도
- d : 각 픽셀의 깊이 정도
- β : 빛의 산란 정도를 조절하는 계수 (안개가 짙을수록 커짐)
2. 비 (Rain)
비는 비줄기(rain streak)와 안개 효과를 동시에 고려하여 다음과 같은 수식으로 모델링된다.

Rain with rain streaks and fog effetc - Rᵢ : 개별 raindrop residuals (비로 인한 잔상, 노이즈 등)
- ∑Rᵢ : 여러 개의 비줄기 효과를 누적한 값
- 나머지 항목은 안개와 동일
3. 저조도 (low light)
저조도 환경은 감마 보정을 통해 구현된다.

gamma Correction - F : 감마 보정을 적용한 이미지 변환 함수 (예: Look-up Table 기반)
- γ (감마값) : 밝기 조절 계수 (낮을수록 어두움)
Adaptive Learning Strategy - 1) Weak constraint Encoder
Weak Constraint Encoder(WCE) 는 간단하게 말하면,
Swin Transformer를 활용하여 adverse scene에서도 robust한 feature를 추출하는 구조이다.논문에서는 비, 안개, 저조도와 같은 악조건(adverse) 환경에서 강건한 인식이 가능하도록,
global + local context를 동시에 학습할 수 있는 Swin Transformer 구조를 사용한다.
이는 ViT 계열 구조 중에서도 계산 효율성과 표현력을 모두 고려한 선택으로 추정된다.작동방식

입력 이미지는 먼저 backbone을 통과하며,
이를 통해 크기가 H/4×W/4×C 인 feature map을 추출한다.
(backbone의 정확한 구조는 논문에 명시되어 있지 않다.)이후 이 feature map은 여러 stage에 걸쳐 아래와 같은 과정을 거친다
Patch Merging → Intra-patch Attention (로컬 정보 학습) → Normal Patch Attention (전역 문맥 학습)
이렇게 추출된 feature 는 Strong constraint Decoder 로 전달된다.
더보기
Swin Transformer는 기존 Vision Transformer에서 이미지 패치를 대상으로 모든 쌍에 대해 Attention을 수행할 경우 계산량이 매우 크다는 단점을 해결하고자 제안된 구조다.
Swin은 "Shifted Window"의 줄임말로, 연산량과 성능을 동시에 확보하기 위한 구조적 개선을 의미한다.
먼저 이미지를 4×4 작은 크기의 local window로 나눈 뒤, 해당 window 내에서만 self-attention을 수행한다 (Layer 1 구조).하지만 이 경우 각 window 내부에서만 정보를 처리하기 때문에, window 간의 문맥(context)을 파악하기 어렵다는 한계가 존재한다.
이를 해결하기 위해 Swin은 다음 layer에서 window를 반칸씩 밀어(shift) 겹치도록 만든 뒤, masked multi-head self attention(MSA)을 수행한다.이 방식을 통해 window 간 정보도 전달되며, 전체적인 문맥 파악이 가능해진다.
이러한 구조 덕분에 Swin Transformer는 ViT 수준의 성능을 유지하면서도 계산량은 대폭 줄이는 데 성공하였다.
Weak constraint Encoder Strong constraint decoder 라는 모듈을 제안한다.
Adaptive Learning Strategy - 2) Strong constraint decoder
Strong constraint decoder(SCD)는 WCE에서 추출한 feature 를 기반으로, scene-level context 를 보정하고 정제하는 역할을 한다. 특히 악조건 환경에서는 객체의 feature 가 왜곡되거나 일부 가려지기에 이러한 scene-aware 하게 보완하는 역할을 한다.
작동방식

Cross Attention WCE의 마지막 stage 에서 출력된 feature 를 Key(K), Value(V) 로 사용하고, 학습 가능한 scene penalization query를 Q로 사용하여 Cross Attention 연산을 수행한다.
이를 통해 SCD는 전체 scene에서 얻은 context 를 기반으로 feature가 오인식 되었을 가능성이 있는 부분에 self-supervised learning 방법으로 패널티를 부여한다.
더보기Self-Supervised Learning
WCE 가 추출한 피쳐와 SCD가 재해석한 feature 간의 차이를 오차로 보고, 이 차이가 크면 잘못 인식되었을 가능성이 높다고 판단하여 Smooth L1 loss 를 통해 패널티를 부여함

예시 
L1 smooth loss Twin Depth Perception
기존 방식들은 객체 주변의 feature만으로 깊이를 예측하는 경향이 있다. 하지만 비, 안개, 저조도 등 adverse condition에서 오차가 커지는 문제가 있다. 이를 해결하기 위해 MonoTDP는 깊이를 두 요소로 나누어 예측한다.
- Object Depth : 객체 자체의 local feature 만으로 예측한 깊이
- Scene Depth : 객체 주변을 포함한 전체 scene context를 반영한 깊이
또한 Depth에 대한 Uncertainty 정보도 참조한다.
작동 방식
Object Depth
- RoI Align을 통해 추출된 7x7 객체 feature 를 Regression하여 예측
Scene Depth
- 위에서 얻은 object feature 를 query 로 사용
- 전체 이미지에서 얻은 scene feature map을 Key/Value 로 사용하여
- Cross-Attention 수행
- 이를 통해 주변 scene 정보까지 반영된 scene depth 예측
Instance Depth
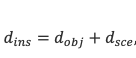
Uncertainty-aware loss
Uncertainty 추정은 MonoTDP에서 깊이 예측의 신뢰도를 정량화하기 위한 요소다. 단순히 깊이 값을 회귀하는 것만으로는 모델이 자신의 예측이 얼마나 확실하게 하는지 알 수 없기에 Laplace 분포 기반의 회귀 방법으로 신뢰도 또한 학습하게 한다.
더보기Laplace distribution

Laplace 분포는 평균을 중심으로 대칭인 확률 분포, 정규분포와 유사하지만 봉우리가 뾰족한 형태를 가진 분포
데이터의 중심값(평균) 주변에서 값이 더 많이 나타나고, 중심에서 멀어질 수록 급격히 감소하는 특성
그렇다면 uncertainty는 해당 수식에서 b(= scale parameter)를 의미한다.
확률 분포의 폭(= scale parameter)은 다음을 의미한다:
- 폭이 좁다 → 특정 값 주변으로 확률이 집중됨 → 예측값이 정확할 가능성이 높다
- 폭이 넓다 → 다양한 값에 확률이 퍼짐 → 예측값이 틀릴 가능성도 크다
해당식의 μ, b 값을 이용하여 depth 를 계산한다.
MonoTDP 는 최종적으로 다음 두 값을 함께 예측한다.
- 깊이값 d_ins: 예측된 instance depth
- 불확실성 u_ins: 해당 깊이값이 얼마나 불확실한지를 나타내는 스칼라
이때 불확실성은 단순한 confidence score가 아니라, loss 계산 과정에 직접 반영되는 정량적 예측값이다.
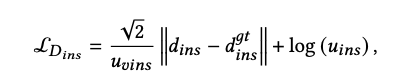
이 값들을 바탕으로 다음과 같이 instance 와 gt 간의 오차를 정의한다.
따라서 최종적인 Depth estimation의 과정은 다음과 같이 정리될 수 있다.

입력 이미지 ↓ Backbone → Feature map ↓ 2D Detection → 바운딩 박스 예측 ↓ RoI Align → 객체 중심 feature (7×7) ↓ ↓ Object Depth 추정 Scene Depth 추정 (Cross-Attention) ↘ ↙ Instance Depth = Object Depth + Scene DepthLoss funciton

최종적인 loss funciton은 다음과 같이 정리할 수 있다.
Loss input L_H Heat map H L_(O_2D ) 2D Offset O_2D 〖L_S〗_2D 2D Size S_2D L_(s_3D ) 3D sice S_3D L_θ Orientation θ L_(O_3D " " ) 3D Offset O_3D L_(D_ins ) d_ins, u_ins L_(smooth_L1 ) 잘못 인식 feature penalty Experiments
- 본 실험은 총 7,481장의 이미지로 구성된 데이터셋을 사용하였으며, 이 중 3,712장은 학습용(Train), 3,769장은 검증 및 테스트용(Val/Test) 으로 사용되었다.
- 성능 평가는 AP_3D_R40 지표를 기준으로 수행되며, 이는 40개의 recall 포인트에서의 평균 정밀도(average precision)를 의미합니다.
- 평가 기준 IoU는 0.8 이상, 난이도는 Easy, Moderate, Hard 세 단계로 구분됩니다.

모든 환경에 대해서 기존 SOTA 대비 우수한 성능을 보였다.

- 이미지 복원 전용 모델 (ex. TransWeather, MSBDN, DCPDN) 로 adverse scene 복원 →
- 복원된 이미지를 MonoTDP의 base 3D detection backbone에 넣어서 3D 객체 탐지 수행 →
- MonoTDP end-to-end 모델과 성능 비교
Ablation Study

- WCE만 추가해도 1.34% 성능 향상
→ adverse condition에서도 강건한 feature 추출에 효과적 - SCD까지 포함하면 더 상승
→ scene-level 제약이 feature를 정제하는 데 도움 - Object Depth + Scene Depth도 단독으로 효과 있지만,
→ WCE/SCD와 결합했을 때 가장 큰 성능 향상을 보임
'AI > 논문리뷰' 카테고리의 다른 글
3D Object Detection from Images forAutonomous Driving: A Survey (0) 2025.04.07 PointNet : Deep Learning on Point Sets for 3D Classification and Segmentation (0) 2025.03.05 논문리뷰 - TransUNet (0) 2025.02.05